Machine Learning et Deep Learning : comment les distinguer ?

À l’heure actuelle, de nombreux secteurs d’activité utilisent la technologie de l’Intelligence Artificielle (IA). Il se trouve cependant que plus d’un se méprennent encore sur le sujet, notamment en ce qui concerne des concepts-clés comme le Machine Learning et le Deep Learning.
En effet, beaucoup pensent que le Machine Learning et le Deep Learning désignent le même processus d’entraînement. Eh bien, c’est une erreur ! Alors, pour mieux appréhender le monde de l’IA, la première chose à faire est de cerner la différence entre ces deux modes d’apprentissage.
Qu’est-ce que le Machine Learning ?
Le Machine Learning (apprentissage automatique) désigne l’intersection entre l’informatique et les statistiques. Dans les faits, l’IA doit s’alimenter en données pour sa mise en place. Ses algorithmes identifient alors des modèles, aussi appelés patterns, dans les informations reçues. Grâce à ces modèles, l’ordinateur intelligent peut réaliser des prédictions efficaces à l’arrivée de nouvelles informations (les catégoriser, par exemple).
Les algorithmes ont une structure relativement simple telle qu’une régression linéaire ou un arbre de décision dans ce domaine. Effectivement, le Machine Learning se base surtout sur des analyses statistiques. Et dans la pratique, l’IA réalise des prédictions à l’aide de patterns pour ensuite tirer des conclusions à partir de nouvelles données collectées. Ainsi, la machine dotée d’IA peut apprendre sans être explicitement programmée.

Comprendre le Deep Learning
Pour faire simple, le Deep Learning (apprentissage profond) indique une évolution du Machine Learning. Son architecture est plus sophistiquée et mathématiquement plus complexe que celle de son prédécesseur.
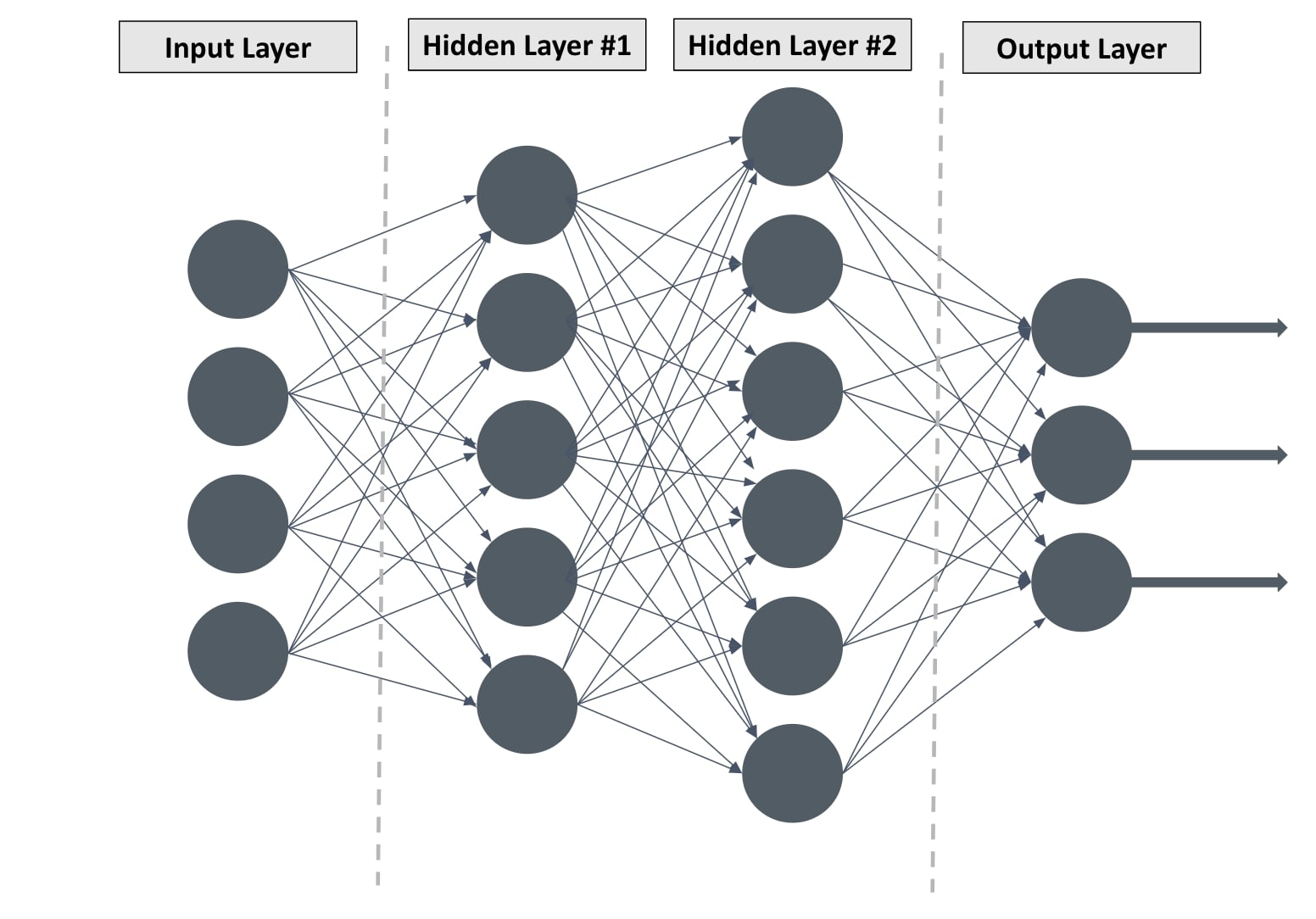
Il dispose en plus des algorithmes dont les capacités d’analyse d’informations sont proches de celles du cerveau humain. Cette prouesse est possible grâce à un réseau neuronal artificiel (ANN). Dans les faits, l’ANN s’inspire du réseau neuronal du cerveau humain. Par conséquent, le processus d’entraînement de l’ordinateur est plus performant comparé à la méthode précédente.
Dans ce cas-là, l’IA repose sur l’ANN qui comporte 3 types de couches : une entrée et une sortie qui renferment des couches intermédiaires. Les strates intermédiaires ou cachées sont les parties qui permettent à la machine d’être plus performante. Plus les couches cachées sont abondantes, plus le réseau de neurones est profond, plus l’IA est efficace. Ce qui explique le nom de la procédure d’entraînement.
À cause d’un manque de ressources IT, le Deep Learning n’a pu réellement se développer que récemment. En effet, l’installation de cette technologie nécessite une puissance de calcul ainsi qu’une quantité d’informations considérable.
Les différences entre le Machine Learning et le Deep Learning
Mise à part la différence de l’organisation de leurs algorithmes, ces deux méthodes d’enseignement de l’IA ont d’autres spécificités.
Un entraînement distinct
En ce qui concerne le Machine Learning, il a besoin d’informations structurées, organisées et donc étiquetées. En d’autres termes, le développeur doit lui fournir les caractéristiques discriminantes des données. Cela est nécessaire pour qu’à l’avenir, l’IA soit capable de classer les informations inconnues similaires. Par ailleurs, le Machine Learning requiert le feed-back du développeur. Ce dernier doit ainsi lui communiquer les erreurs de classification et les corriger.
En revanche, le Deep Learning n’a pas besoin d’informations organisées. C’est qu’il détermine lui-même les caractéristiques des données qu’il reçoit. Il n’a pas non plus besoin de l’assistance directe d’un développeur. Au fil du temps, il est capable d’évoluer de lui-même grâce aux appréciations des utilisateurs.

Des besoins particuliers
Pour ce qui est de l’apprentissage profond, il n’est efficace qu’à partir de millions de données. Il a de même besoin d’un temps d’évolution relativement conséquent. Sans compter que cet entraînement repose sur une puissance de calcul énorme. À titre de comparaison, avec un ordinateur du quotidien, la procédure prendrait plusieurs mois, voire plusieurs années. Le prix de sa mise en place est en conséquence plus élevé.
Quant à l’apprentissage automatique, il nécessite seulement des milliers d’informations. A propos du temps, celui-ci en demande bien moins par rapport au précédent. Ce processus nécessite pareillement peu de ressources informatiques (IT) ainsi qu’un budget plus raisonnable.
En bref, le Deep Learning est une sous-catégorie plus spécifique du Machine Learning, mais il est différent de ce dernier. Néanmoins, les deux ont un point commun : donner aux ordinateurs la capacité de penser intelligemment. Au fait, la première méthode s’avère utile lorsque les données à traiter sont non structurées et colossales. Ce qui permet à l’IA de résoudre divers problèmes avec plus d’aisance et d’efficacité. Nonobstant, le budget nécessaire à son développement est non négligeable, d’où la nécessité de recourir à la seconde méthode lorsque c’est possible.
.